Plots
Documentation
Policy Legend
Layout
This dashboard functions as an interactive simulation report. Users can create liver Continuous Distribution (CD) policies with different rating scales and attribute weights, and see how they perform in simulation across a host of different metrics. Details on the simulation methodology are provided in the "Simulation" page.
The dashboard consists of three sections:
- Navigation Panel (left): Used to navigate between different plot and documentation pages.
- Workspace (main): Displays plots of different simulated metrics for all policies.
- Toolbox (bottom): Used to add/edit/remove policies from all plots.
Workspace Plots
The dashboard comes pre-populated with plots for current Acuity Circles policy (OPTN 2023) and an example Continuous Distribution policy with balanced weights (Balanced CD).
The "Main Metrics" page shows a condensed view of top-level metrics, e.g. overall mortality and transplant rates, transport distance, etc. Other plot pages contain deep dives of outcomes for different demographics, by geography, pediatric status, etc.
The "Custom Plots" page allows the user to create custom plots that are not included in the above. Clicking the "+" button on the empty plot card will bring up a dialog to select the type of plot and metrics to be plotted. These plots can also be edited by clicking on the pencil icon on their top right, or removed from the page by clicking the backspace icon.
Policy Toolbox
The policy toolbox, pictured below, is used to create and edit policies.
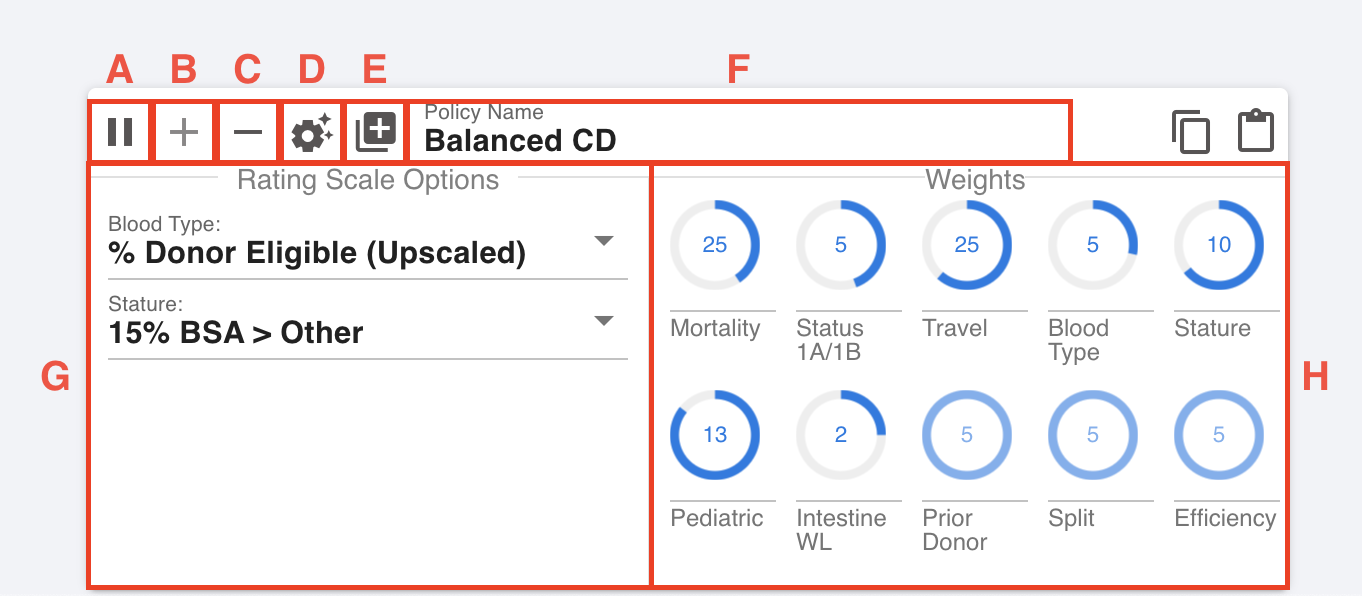
A. Toggle real time normalization
B. Add/update policy
C. Remove policy
D. Optimize policy
E. Load policy
F. Name text box
G. Rating scale menus
H. Attribute weight knobs
Loading a policy
There are several way to load an policy in the toolbox.
- Clicking on a policy in the Policy Legend or any plot will load it into the toolbox, overwriting the name (F), rating scale options (G) and attribute weights (H).
- Certain pre-defined policies (e.g. OPTN 2023, Balanced CD and variants) can be loaded by clicking the "Load policy" button (E) and subsequent pop-ups. Policies can be accessed and re-added here even after they have been removed from the workspace.
- Typing the name of a pre-defined policy in the name text box (F) will load it in the toolbox.
Editing a policy
The selected policy can be edited one of two ways. The drop-down menus in (G) will change the rating scale being used for a particular attribute (only for attributes that have multiple options). The knobs in (H) will change the weight associated with any attribute (within a pre-specified range) in the overall CAS formula. Note: these changes will not be reflected in the plots until the policy is added to the workspace (see Adding/Updating a policy).
By default, when any weight knob is changed, the dashboard will automatically adjust the remaining weights to sum to 100%. This behavior can be turned off by clicking on the "toggle real time normalization" button (A) to allow for finer-grained control. Note, however, that the weights will still be normalized when the policy is added to the workspace.
Note: In some cases, the normalization may fail if the adjusted weights are not in the allowable ranges. Such policies cannot be simulated, and the dashboard will show a pop-up error message. In this case, one may reset the weights manually or by loading a valid policy.
Adding/Updating a policy
Clicking the "Add/update policy" button (B) will update the workspace to reflect any weight/option changes made in the toolbox (see above). If the policy name (F) already exists in the plot space, then the policy is overwritten and the plots redrawn with the same color. If the policy name does not exist, it is added as a new policy with a new color.
Note: pre-defined policies, e.g. Balanced CD, cannot be overwritten. Editing them will clear the name text box (F) so that they can be added under a new name.
Removing a policy
Any policy can be removed from plots by clicking on it to load into the toolbox, and clicking the "Remove policy" button (C). Policies that were removed can be added back as described in Loading a policy.
Optimizing a policy
Clicking the "Optimize policy" button (D) will bring up the optimization pop-up dialog. Here, one can assign key metrics as "primary" or "secondary" objectives for the optimization. Alternatively, one may specify what percentage worse than current policy (OPTN 2023) the metric is allowed to be. One may also optionally limit what rating scales the optimizer can use for a particular attribute (if many are available).
When the "Optimize" button is clicked, the dashboard will search through simulated CD policies to find one that satisfies the specified criteria. The optimized policy's rating scale options and attribute weights will be automatically loaded into the toolbox, where it can be optionally renamed (F) and added to the workspace (B).
Note: Multiple metrics can be assigned to the same objective priority bucket (primary or secondary). In this case, the optimization will prioritize all of them equally, likely resulting in smaller improvements across the board than if one were to optimize each individually.
MITSAM
All simulation and optimization results on this website were generated by MITSAM, a discrete-event simulator based on the most recent publicly-available version of SRTR's Liver Simulated Allocation Model (LSAM) (version 2019, used for the development of Acuity Circles).
MITSAM's simulation methodology is identical to LSAM's, and has been extensively validated to produce the same simulation results (up to randomness) under Acuity Circles allocation. Algorithmic enhancements allow MITSAM to simulate Continuous Distribution (CD) policies orders of magnitude faster than LSAM, which is necessary for efficient optimization. These enhancements are purely computational, and do not impact the output of the simulator.
Notably, MITSAM uses the same cohort as LSAM 2019 (candidates and donors from 2011-2016), as well as the same waitlist mortality, organ offer acceptance, transport, and transplant outcomes/relisting models. These will be updated as newer versions are released by the SRTR.
Significant changes were made only to the allocation priority component of LSAM 2019, namely:
- Implementation of a Continuous Distribution allocation policy with the committee's chosen attributes and scales.
- Retrospective calculation of lab MELD 3.0/PELD-Cr for the candidate cohort.
- Update of Acuity Circles policy to reflect post-2019 changes:
a. Allocation based on MELD 3.0/PELD-Cr instead of MELD-Na/PELD.
b. Increased priority for MELD<30, blood type B candidates when the donor is blood type O.
c. Diagnosis points in sorting criteria for Status 1B classification groups.
d. Pediatric and exception points in sorting criteria for MELD classification groups.
Limitations
Changes in listing and organ acceptance behavior
As with any counterfactual simulator, MITSAM and LSAM use behavioral models to predict acceptance or not for organ offers that were never made in reality. These models are trained on historical match run data, and aim to extrapolate from the underlying acceptance patterns observed in the past. While we can assess their historical accuracy, we cannot know how accurate they will be under a new policy (e.g. continuous distribution), where candidates and centers adjust their behavior to the new profile of offers they are receiving. Nonetheless, LSAM predictions have been shown to be directionally correct during previous policy changes, despite behavioral changes, and are likely to be so under CD as well.
Pediatric offer acceptance under CD
The above limitation is particularly important as it relates to pediatric candidates, who could see a significant shift in the age of donors offered to them under CD. Historical OPTN policies have always heavily prioritized pediatric candidates when the donor is also pediatric. As such, the organ acceptance model is trained to predict behavior when the majority of offers made to pediatric candidates is from pediatric donors.
This is likely to change under the current CD proposal, as pediatric candidates receive a uniform priority boost and are at the top of a match run regardless of the donor's age. While we would expect acceptance rates to go down for these types of offers, this is only partially reflected in the historical data the acceptance model was trained on. Therefore accepted offers that result in a transplant may be over-estimated for pediatric candidates in LSAM.
Note: Any overestimation is likely to be less severe if modeling a CD policy that only gives pediatric candidates a boost for pediatric donors (i.e. through the use of a donor modifier). In this case, the distribution of offers seen by pediatric candidates in simulation will more closely resemble the historical distribution that the acceptance model was trained on.
Liver-intestine transplants are not modeled
As with LSAM, the optimization does not explicitly model joint liver-intestine transplants. Liver-intestine candidates are flagged in the cohort and given CAS points under the relevant attribute. However they are treated no differently than liver-alone candidates in terms of acceptance behavior or post-TX outcomes. Note that some differences are still captured implicitly though related factors -- e.g. the higher MELD 3.0 or exception scores that these candidates typically receive. Nonetheless, caution should be taken in comparing transplant and mortality rates for this sub-population.
Segmental liver transplants and reallocation are not modeled
Similarly, neither LSAM nor MITSAM explicitly model segmental transplants or reallocation of the remaining segment to a different candidate. Candidates who would accept a segmental liver are noted in the cohort, and given CAS points under the relevant attribute. However they are not treated any differently from whole liver transplants in terms of acceptance or post-transplant behavior.
Prior living donor information is not available
Information on whether a candidate was a prior living donor has not been collected historically for liver patients. As such, the simulator cannot predict outcomes for this sub-population.
Introduction
The dashboard supports simulating and optimizing Continuous Distribution (CD) policies that differ not only in the relative attribute weights, but also in the rating scales being used for each attribute.
Rating scales determine how candidates are awarded points for a particular attribute, say mortality or travel efficiency (as opposed to weights, which determine how the attributes are combined into a single score). Based on candidate/donor characteristics, a rating scale will assign each candidate a rating between 0 and 1, representing what fraction of the total points available to the attribute the candidate is eligible to get.
This page describes the rating scale options that are modeled in the dashboard for each liver CD attribute:
- Mortality
- Status 1A/1B
- Travel efficiency
- Blood type
- Stature
- Pediatrics
- Liver-intestine
- Efficiency (not currently implemented)
- Split liver (not currently implemented)
- Prior living donor (not currently implemented)
Currently, the blood type and stature attributes are the only ones with different rating scale options. As the committee deliberates further, additional options will be added for other attributes as modeling allows.
A note on comparing rating scales
The challenge with comparing rating scale options, even for a single attribute, is that they do not exist in isolation. It is their interaction with the weight of the attribute, as well as all other attributes, that determines a candidate's priority. To the extent possible, care should be taken to control for other attributes when comparing simulations of different rating scales.
As a simple example, consider comparing two blood type rating scales: (i) blood type O candidates get 1.0, other types get 0.0, vs. (ii) blood type O get 0.5, while other types get 0.0. Concretely, this means that a policy with 20% CAS weight on blood type will award 20 points to O candidates if the first scale is used, but only 10 if the second scale is used.
Now note that it is still possible for an O candidate to receive 20 blood type points using the second rating scale; if the policy has CAS weight of 40% for blood type instead of 20%. While the blood type points are the same for these two policies, overall priority is not: in the former case, a candidate will be able to get up to 80 points for other attributes, while in the latter only 60. In other words, the same 20 blood type points for O candidates will count a lot more with the second scale.
As such, it is most often useful to compare rating scales while holding attribute weights fixed on the dashboard. To this end, attributes with multiple rating scale options have been designed to be "comparable" when the weight assigned to the attribute is the same.
See, for example, the stature rating scale, where the committee is evaluating whether candidates in the bottom 5% of BSA require additional priority compared to the bottom 5-15% (when the donor is also short stature). Concretely, the two rating scales available on the dashboard: (i) 1.0 for the bottom 5% of BSA, 0.5 for the bottom 5-15% of BSA, 0.0 otherwise vs. (ii) 0.5 for the bottom 15%, 0.0 otherwise. For a given weight on stature, say 10%, the dashboard can thus compare outcomes when giving the bottom 5% of BSA an extra 5 points of priority, in addition to the 5 they get for being in the bottom 15%.
Mortality attribute
Goal: To provide increased access to candidates with higher predicted mortality rate, according to a medical urgency score.
Option 1: Lab MELD 3.0 / PELD-Cr
Points are awarded according to the following equation, provided by the SRTR, which estimates 90 day mortality as a function of a candidate's status and lab MELD 3.0/PELD-Cr score:
| Candidate Status | Rating |
|---|---|
| 1A | 0.536 |
| 1B | 0.220 |
| Other | 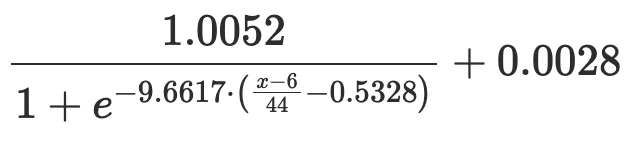 where x is the candidate's lab MELD 3.0 or PELD-Cr score |
Note: In simulation, the rating scale used a candidate's raw lab MELD 3.0 or PELD-Cr score (depending on registration age), not including any historically granted exception scores.
Status 1A/1B attribute
Goal: To provide additional urgency-based access for Status 1A and 1B candidates.
Option 1: 1A > 1B > M/P
Points are awarded based on a candidates status and diagnosis:
| Status | Diagnosis | Rating |
|---|---|---|
| 1A | Any | 1.00 |
| 1B | Decompensated chronic liver disease | 0.85 |
| 1B | Hepatoblastoma | 0.70 |
| 1B | Metabolic disease | 0.55 |
| 1B | Other | 0.00 |
| Other | Any | 0.00 |
Travel efficiency attribute
Goal: To prioritize placements that efficienctly allocate organs in terms of proximity between the donor hospital and candidate listing center.
Option 1: Lung Rating Scale
A draft rating scale, identical to the one used for prxoximity efficiency in lung continuous distribution. Points are awarded based on the following equation:
| Distance in nm | Rating |
|---|---|
| x < 45 | 1.000 |
| 45 < x < 90 | 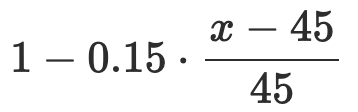 |
| x >= 90 |  |
Values for some example distances are given below for reference:
| Distance (nm) | Rating |
|---|---|
| 45 | 1.000 |
| 90 | 0.850 |
| 200 | 0.842 |
| 500 | 0.809 |
| 1000 | 0.680 |
| 1500 | 0.438 |
| 2000 | 0.195 |
| 3000 | 0.002 |
Blood type attribute
Goal: To provide equal access to transplant regardless of blood type.
Option 1: Upscaled Candidate Eligibility
Based on the estimated proportion of the donor pool that a candidate blood type is ineligible for, scaled to a 0-1 range.
| ABO | # Donors | # Compatible Donors | Proportion Incompatible | Rating |
|---|---|---|---|---|
| O | 9,166 | 9,166 | 0.5096 | 1.0000 |
| A | 6,888 | 16,054 | 0.1411 | 0.2769 |
| B | 2,131 | 11,297 | 0.3956 | 0.7763 |
| AB | 507 | 18,692 | 0.0000 | 0.0000 |
| Total | 18,692 |
Note: The cohort for the calculation was between Feb. '20 and Feb' 22.
Option 2: Candidate-to-Donor Ratio
Based on the ratio of candidates of the blood type to compatible donors, scaled to a 0-1 range.
Qualitatively, the scale estimates how many candidates of blood type X are listed per compatible donor. Compared to the previous option, type A candidates now get more points than type B candidates. Even if Bs are compatible with fewer donors overall, there's fewer of them competing for those compatible donors.
| ABO | # Candidates | # Donors | # Compatible Donors | Ratio | Rating |
|---|---|---|---|---|---|
| O | 17,957 | 9,166 | 9,166 | 1.9591 | 1.0000 |
| A | 14,221 | 6,888 | 16,054 | 0.8858 | 0.4323 |
| B | 4,398 | 2,131 | 11,297 | 0.3893 | 0.1697 |
| AB | 1,280 | 507 | 18,692 | 0.0685 | 0.0000 |
| Total | 37,856 | 18,692 |
Note: The cohort for the calculation was between Feb. '20 and Feb' 22.
Stature attribute
Goal: To prioritize adult candidates of small stature in order to provide more equal access to transplant regardless of candidate size.
Note: Stature is determined by calculating the Body Surface Area (BSA) according to the Mosteller equation:

Option 1: 15% BSA > Other
This scale is subject to a donor modifier, and awards the following points only if the donor is >18 years old and in the bottom 10th percentile of BSA (< 1.651):
| Listing Age | BSA | Value |
|---|---|---|
| >= 18 | 0-15% ( <= 1.713) | 0.5 |
| >= 18 | 15-100% ( > 1.713) | 0.0 |
| < 18 | Any | 0.0 |
If the donor is pediatric or not in the bottom 10% of BSA, no points are awarded to any candidate.
Note: The highest rating awarded for this scale is 0.5, rather than 1.0, for reasons described in a note on comparing rating scales.
Option 2: 5% BSA > 15% BSA > Other
Similar to the above, but provides additional priority for candidates in the bottom 5% of BSA.
This scale is subject to a donor modifier and awards the following points only if the donor is >18 years old and in the bottom 10th percentile of BSA (< 1.651):
| Listing Age | BSA | Value |
|---|---|---|
| >= 18 | 0-5% (x <= 1.573) | 1.0 |
| >= 18 | 5-15% (1.573 < x <= 1.713) | 0.5 |
| >= 18 | 15-100% ( > 1.713) | 0.0 |
| < 18 | Any | 0.0 |
If the donor is pediatric or not in the bottom 10% of BSA, no points are awarded to any candidate.
Pediatric attribute
Goal: To prioritize access to transplant for children (age <18 years at the time of registration).
Option 1: Binary Scale
Awards full points to pediatric candidates regardless of donor age:
| Listing age | Rating |
|---|---|
| < 18 | 1.0 |
| >= 18 | 0.0 |
Important Note: Simulated policies using this rating scale may over-estimate pediatric transplant rates, particularly if the attribute weight for pediatrics is high. This is due to limitations in LSAM's organ offer acceptance model, which is trained on historical policies that did not expose pediatric candidates to high volumes of adult offers. A deeper explanation is given on the "Simulation Limitations" page.
Liver-Intestine attribute
Goal: To prioritize liver-intestine candidates over liver-alone candidates.
Important note: LSAM does not currently model liver-intestine transplants any differently than liver-alone transplants. Liver-intestine candidates can be identified in the cohort and prioritized in simulated allocation, however their waitlist mortality, organ offer acceptance and post-transplant outcomes are determined by the same models as liver-alone candidates. More tailored modeling may be possible, but would require a data request to the SRTR to study its feasibility and update LSAM. In absence of additional modeling, dashboard analyses will focus on waitlist mortality and access metrics (e.g. # apperances of liver-intestine candidates in the top-10 of a match run) rather than transplant rates or post-transplant outcomes.
Option 1: Ideal Donor Modifier
Liver-intestine candidates are provided a certain amount of points regardless of the donor, and increased priority if the donor is "ideal":
- Not DCD
- BMI <= 30
- Age <= 40
- No history of diabetes.
Points are awarded to candidates as follows:
| Candidate | Donor | Rating |
|---|---|---|
| Liver-intestine | Ideal | 0.67 |
| Liver-intestine | Not ideal | 0.33 |
| Liver-alone | Any | 0.00 |
Note: No candidate is awarded the full rating of 1.0 under this scale. This is to allow easier comparisons to a different proposed scale, wherein pediatric liver-intestine candidates receive additional priority when the donor is ideal. This second option will be implemented in future iterations of the dashboard pending feasibility.
Efficiency attribute
Goal: To prioritize allocation livers in the most efficient manner.
Important Note: UNOS is currently formulating rating scale proposals for this attribute, incorporating feedback from the Committee and Expeditious taskforce. As such, there is not rating scale currently implemented on the dashboard, and a placeholder weight of 5% is fixed for the attribute.
Split liver attribute
Goal: To prioritize candidates who are willing to accept a split liver with donors whose livers are able to be split.
Important note: LSAM does not currently model split liver transplants and subsequent reallocation. Modeling split liver transplants may be possible, but would require a data request to the SRTR to study its feasibility and update LSAM. As such, there is current no rating scale implemented on the dashboard, and a placeholder weight of 5% is fixed for the attribute.
Future iterations of the dashboard may implement the committee's chosen rating scale, in order to evaluate to what extent splittable livers are directed towards candidates willing to accept them (e.g. by looking at how often they appear in the top-10 of a match run). In this case, however, users should note that split liver transplants will be treated no differently than whole liver transplants in simulation, in terms of organ offer acceptance or post-transplant outcomes.
Prior Living Donor attribute
Goal: To prioritize candidates who were previous living donors.
Important note: Data on prior living donors has not been historically collected by the OPTN for liver candidates, and can therefore not be included in modeling. As such, there is no rating scale implemented on the dashboard, and a placeholder weight of 5% is fixed for the attribute.
Simulated Metrics
The dashboard reports a variety of different metrics for each policy, overall and for various candidate/donor stratifications.
For pre-defined and optimized policies, plots show the mean metric value over 50 iterations of simulation, with error bars for the 5th and 95th percentile. When new policies are added from the toolbox, e.g. by manually modifying the weights, nearest-neighbor machine-learning models are used to estimate simulated outcomes and error bars.
Definitions and examples of how each metric is calculated for a given candidate/donor group are listed below:
- Group Size metrics
- Mortality metrics
- Transplant metrics
- Travel metrics
- Match run metrics
- Disparity metrics
Group Size Metrics
Total Wait Time (yrs)
Total waitlist time (at status 1A, 1B, any M/P, inactive) accrued by candidates of a group over the simulation.
Examples: 300 years of wait time accrued by blood type O candidates. 200 years of wait time while HCC by any candidate.
Note 1: When the stratified candidate characteristic can change over time, e.g. HCC exception status or MELD band, we only count time of any patient while that characteristic was active.
Note 2: Does not count any time accumulated before the simulation began.
Total Active Time (yrs)
Total active waitlist time (at status 1A, 1B, any M/P) accrued by candidates of a group over the simulation. Does not include inactive time.
Examples: 200 years of active time accrued by blood type O candidates. 100 years of active time while HCC by any candidate.
Note 1: When the stratified candidate characteristic can change over time, e.g. HCC exception status or MELD band, we only count time of any patient while that characteristic was active.
Note 2: Does not count any time accumulated before the simulation began.
Total Urgent Time (yrs)
Total urgent waitlist time (at status 1A, 1B, or M/P>15) accrued by candidates of a group over the simulation. Does not include inactive time or time at MELD 3.0/PELD-Cr < 15.
Examples: 150 years of urgent time accrued by blood type O candidates. 200 years of urgent time while under HCC exception by any candidate.
Note 1: When the stratified candidate characteristic can change over time, e.g. HCC exception status or MELD band, we only count time of any patient while that characteristic was active.
Note 2: Does not count any time accumulated before the simulation began.
Total Wait Time (%)
The total wait time of a group, expressed as a percentage of total wait time of all groups.
Examples: Blood type O candidates accrued 52% of total wait time. Candidates accrued 20% of total wait time while under an HCC exception.
Total Active Time (%)
The active wait time of a group, expressed as a percentage of total active time of all groups.
Examples: Blood type O candidates accrued 51% of total active time. Candidates accrued 25% of total active time while under an HCC exception.
Total Urgent Time (%)
The urgent wait time of a group, expressed as a percentage of total urgent time of all groups.
Examples: Blood type O candidates accrued 53% of total urgent time. Candidates accrued 23% of total urgent time while under an HCC exception.
Waiting Ever (#)
Number of candidates of a group ever on the waitlist (i.e. those contributing any amount towards total wait time).
Examples: 3000 blood type O candidates were ever on the waitlist. 2000 candidates were ever under an HCC exception.
Active Ever (#)
Number of candidates of a group ever active on the waitlist (i.e. those contributing any amount towards total active time).
Examples: 2900 blood type O candidates were ever active on the waitlist. 1900 candidates were ever under an HCC exception while active.
Urgent Ever (#)
Number of candidates of a group ever urgent on the waitlist (i.e. those contributing any amount towards total urgent time).
Examples: 2500 blood type O candidates were ever urgent on the waitlist. 1500 candidates were ever under an HCC exception while active and urgent.
Mortality Metrics
Number of WL Deaths
The number of waitlist deaths of a group, either while on the waitlist or within 30 days of being removed. Does not include deaths after receiving a simulated transplant.
Examples: 800 blood type O candidates died on the waitlist. 200 candidates died on the waitlist with an HCC exception while on the waitlist or within 30 days of being removed.
Note: This count includes deaths within 30 days of being removed for any reason, not just for being too sick to transplant.
Percent of WL Deaths
The WL Deaths [#] of a group, expressed as a percentage of all waitlist deaths.
Examples: 45% of waitlist deaths were blood type O candidates. 30% of waitlist deaths were while the candidate was under an HCC exception.
Note: This is not the same as the percentage of blood type O candidates that died on the waitlist.
WL Death Rate
The WL Deaths [#] of a group, divided by the total wait time of that group.
Examples: 0.1 deaths / patient-year for blood type O candidates (800 deaths divided by 8,000 total years on the waitlist).
Note: Waitlist mortality is normalized by total wait time, as opposed to active or urgent time, because candidates can die while inactive.
Died 2Yr Post-Tx
Number of candidates of a group that were transplanted and expected to die within two years due to graft failure.
Examples: 300 transplanted blood type O candidates expected to die within 2 years of TX. 100 candidates transplanted while under an HCC exception expected to die within 2 years of TX.
Note 1: A death is not counted if a candidate receives a transplant, relists due to expected graft failure, and receives another transplant.
Note 2: Expected time to graft failure/death is estimated using LSAM's post-transplant outcome model.
Transplant Metrics
Number of Transplants
Number of transplants for a particular group.
Examples: 4000 transplants to blood type O candidates. 1000 transplants from marginal donors. 1000 transplants from pediatric donors to pediatric recipients.
Percentage of Transplants
The transplants (#), expressed as a percentage of total transplants.
Examples: 40% of transplants were to blood type O candidates. 20% of transplants were from marginal donors. 70% of transplants from pediatric donors were to pediatric recipients.
Note: This is not the same as the percentage of blood type O candidates that received a transplant.
TX Rate (Act)
The transplants (#), divided by the total active time of that group.
Examples: 0.5 transplants per patient-year for blood type O candidates (4000 transplants divided by 8000 years of active time).
TX Rate (Urg)
The transplants (#), divided by the total urgent time of that group.
Examples: 0.8 transplants per patient-year for blood type O candidates (4000 transplants divided by 5000 years of urgent time).
Median Time to Tx (Act)
The median active time on the waitlist at time of transplant, among all candidates of the group that received a transplant.
Examples: the median pediatric TX recipient had spent 50 days active on the waitlist.
Note: The calculation only includes candidates who received a transplant. Waitlisted candidates who did not receive a transplant (and may have been waiting for a significant amount of time) are not included.
Median Time to Tx (Urg)
The median urgent time on the waitlist at time of transplant, among all candidates of the group that received a transplant.
Examples: the median pediatric TX recipient had spent 30 days active and at status 1A/1B or MELD>15 on the waitlist.
Note: The calculation only includes candidates who received a transplant. Waitlisted candidates who did not receive a transplant (and may have been waiting for a significant amount of time) are not included.
Lab MELD 3.0/PELD-Cr at Tx (Med, 25th%, 75th%)
The median (or 25th/75th percentile) of lab MELD 3.0/PELD-Cr at transplant for candidates of a group.
Examples: Transplanted blood type O candidates had a median lab MELD 3.0/PELD-Cr of 31.5.
Travel Metrics
Distance (Med, 25th%, 75th%)
The median (or 25th/75th percentile) of distance between the transplant center and donor hospital for this group, in nautical miles (nm).
Examples: The median distance traveled by organs going to blood type O candidates was 200nm. The 25th percentile of distance traveled by organs from marginal donors was 100nm. The 75th percentile of distance traveled by organs going to compatible blood type was 300nm.
Time (Med, 25th%, 75th%)
The median (or 25th/75th percentile) of expected travel time between the transplant center and donor hospital for this group, in hours.
Examples: The median travel time for organs going to blood type O candidates was 1.5hrs. The 25th percentile of travel time for organs from a marginal donor was 1.2hrs.
Note: Travel times are estimated by LSAM's transportation model, which use historical averages of transport times between any center and hospital.
Organs Flown (%)
Percentage of transplants for a group where the organ is flown to the candidate's center.
Examples: 75% of transplants to blood type O candidates are expected to be flown. 30% of transplants from marginal donors are expected to be flown.
Note: Expected mode of travel (car, helicopter, airplane) is specified for every center/hospital by LSAM's transportation model.
Match Run Metrics
Number Accepted by Seq-10
Number of transplants from a group that where the accepting candidate was in the top 10 positions of a match run.
Examples: 500 transplants from marginal donors were accepted in the top-10 of the match run. 900 transplants from pediatric donors to pediatric candidates were accepted in the top-10 of the match run.
Percent Accepted by Seq-10
The Accepted by Seq-10 (#) for a group, expressed as a percentage of all transplants of that group.
Examples: 40% of transplants from marginal donors were accepted in the top-10 of the match run (400 out of 1000). 90% of transplants from pediatric donors to pediatric recipients were accepted in the top-10 of the match run (900 out of 1000).
Number Top-10 Appearances
Number of match runs for which at least one candidate of a given group appeared in the top 10 positions of a match run.
Examples: 5000 match runs had any blood type O candidate in the top-10. 400 match runs had a candidate with MELD 3.0 between 6 and 14 in the top-10. 4000 match runs had any blood type identical candidate in the top-10.
Note 1: If more than one candidate of the group appears in the top-10, they are not double counted.
Note 2: If an organ is accepted before the 10th position, but a candidate of this group appears only after that position, they are still counted.
Top-10 Appear Rate (Act)
The Top-10 Appear (#) of a group, divided by the total active time of that group.
Examples: 0.625 appearances in the top-10 per patient-year for blood type O candidates (5000 match runs divided by 8000 total active years).
Top-10 Appear Rate (Urg)
The Top-10 Appear (#) of a group, divided by the total urgent time of that group.
Examples: 1.0 appearances in the top-10 per patient-year for blood type O candidates (5000 match runs divided by 5000 total urgent years).
Sequence # at Tx (Med, 90th%)
The median (or 90th percentile) sequence number/position at which transplants of the group were accepted.
Examples: The median transplant to a blood type O candidate was accepted at position 7 of the match run. The 90th percentile transplant from a marginal donor was accepted at position 23 on the match run.
Center # at Tx (Med, 90th%)
The median (or 90th percentile) center number at which transplants of the group were accepted. The center number counts how many unique transplant centers (rather than candidates) the organ was offered to until it was accepted.
Examples: The median transplant to a blood type O candidate was accepted by the 3rd center it was offered to. The median transplant from a marginal donor was accepted by the 4th center it was offered to.
Note: If transplant is accepted at position 4, with center A appearing in positions 1,2,4 and center B at 3, then the center number is 2 (i.e. A is not considered a new center).
Disparity Metrics
In addition to calculating the above metrics for individual groups, when metrics are normalized (i.e. on the same scale for different groups), the dashboard will calculate disparities across groups.
Note: Reducing disparities between groups, e.g. regions or diagnosis, down to a single number can miss some nuances. However it is often useful as a starting point for minimizing disparities in optimization.
The following metrics admit disparity calculations:
- WL Death Rate
- TX Rate (Act)
- TX Rate (Urg)
- Median Time to Tx (Act)
- Median Time to Tx (Urg)
- Median lab MELD 3.0/PELD-Cr at Tx
- Median distance
- Median travel time
- Top-10 Appear Rate (Act)
- Top-10 Appear Rate (Urg)
These are calculated from the individual groups in one of three ways:
- Weighted standard deviation (WSD), weighted by total active time - only for candidate stratifications.
- Unweighted standard deviation (SD) - for non-candidate stratifications.
- Difference between minimum and maximum (MinMax).
For example, consider stratification by candidate blood type:
| Can ABO | TX Rate | Total Active Time (yrs) |
|---|---|---|
| O | 1.5 | 1000 |
| A | 2.0 | 500 |
| B | 1.5 | 500 |
| AB | 3.0 | 200 |
The standard deviation of transplant rates is approximately 0.61.
The weighted standard deviation is approximately 0.45.
The min-max difference is 3 - 1.5 = 1.5.
Rating Scale Options
Weights